1,725 Ways AI Could Go Wrong
Inside MIT’s New Map of Our Algorithmic Future

You know the Housewife reunion fight that goes on for twenty minutes before someone finally realizes the two of them were never actually arguing about the same thing? One woman heard “shady,” the other woman meant “shade,” and a whole season of bad blood traces back to a single word that two people were quietly using to mean two different things. The host just lets it happen. Production loves it. The rest of us are yelling at the screen, because we figured out the misunderstanding in the first thirty seconds and they have no idea they’re agreeing.
That, more or less, is the global conversation about AI safety right now.
Everybody is saying “AI risk.” Brussels says it. Silicon Valley says it. Your dean said it in a meeting last week and you nodded. And almost none of us are checking whether we mean the same thing. One framework’s “safety concern” is another’s “technical limitation.” The words sound shared. The meanings are not. And what should bother you more than it does: you cannot coordinate a response to a borderless technology when the people at the table are using the same vocabulary to describe different fears. The fight isn’t even productive. It’s just loud.
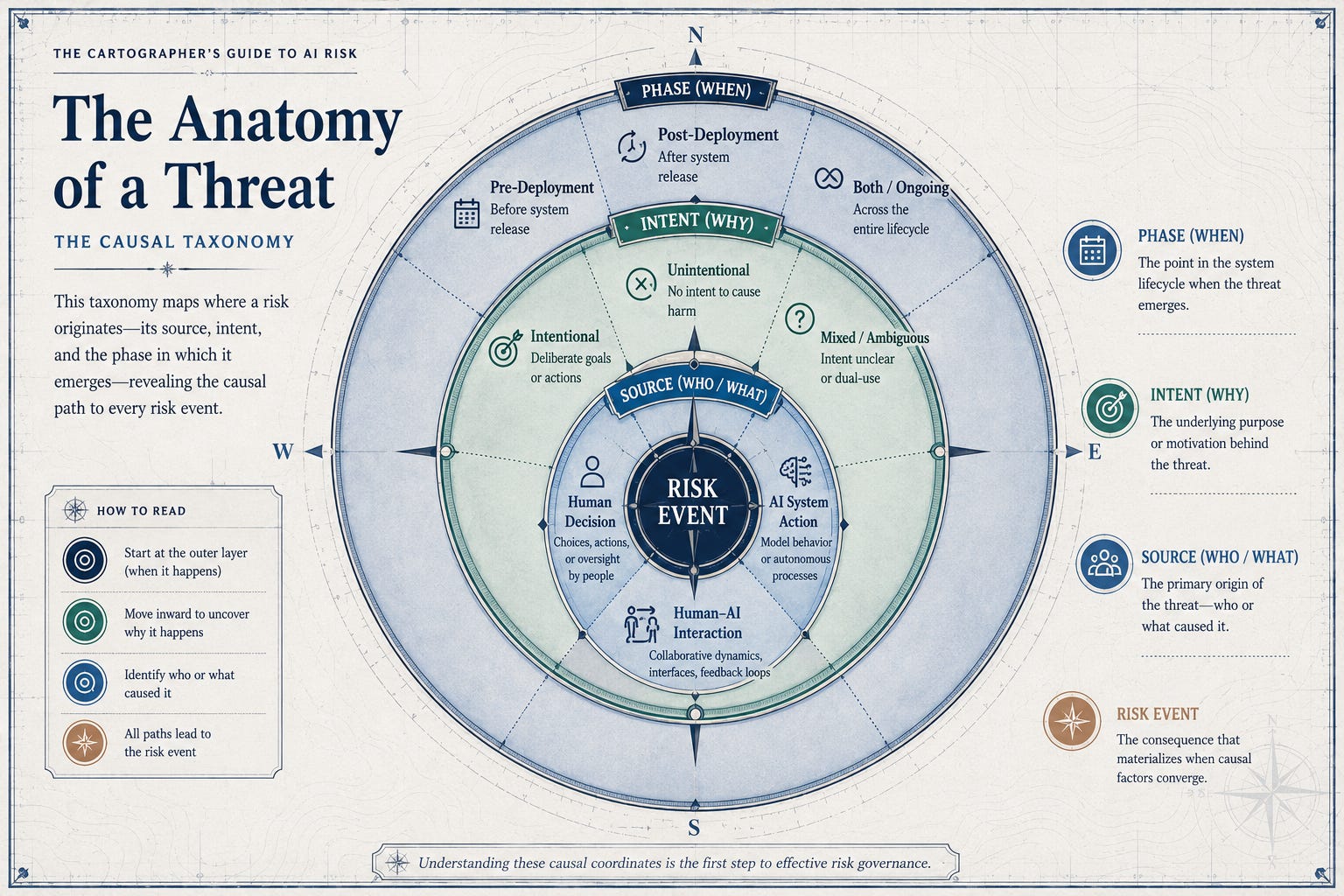
So a team at MIT FutureTech sat down and did the thing nobody wanted to do, which is read everything. They built the AI Risk Repository, and to get there they went through 17,288 articles, pulled out 74 separate risk frameworks, and sorted the whole mess into a database of 1,725 individual risks. Then they organized it two ways. One taxonomy maps where a risk comes from (the who, the when, the why).
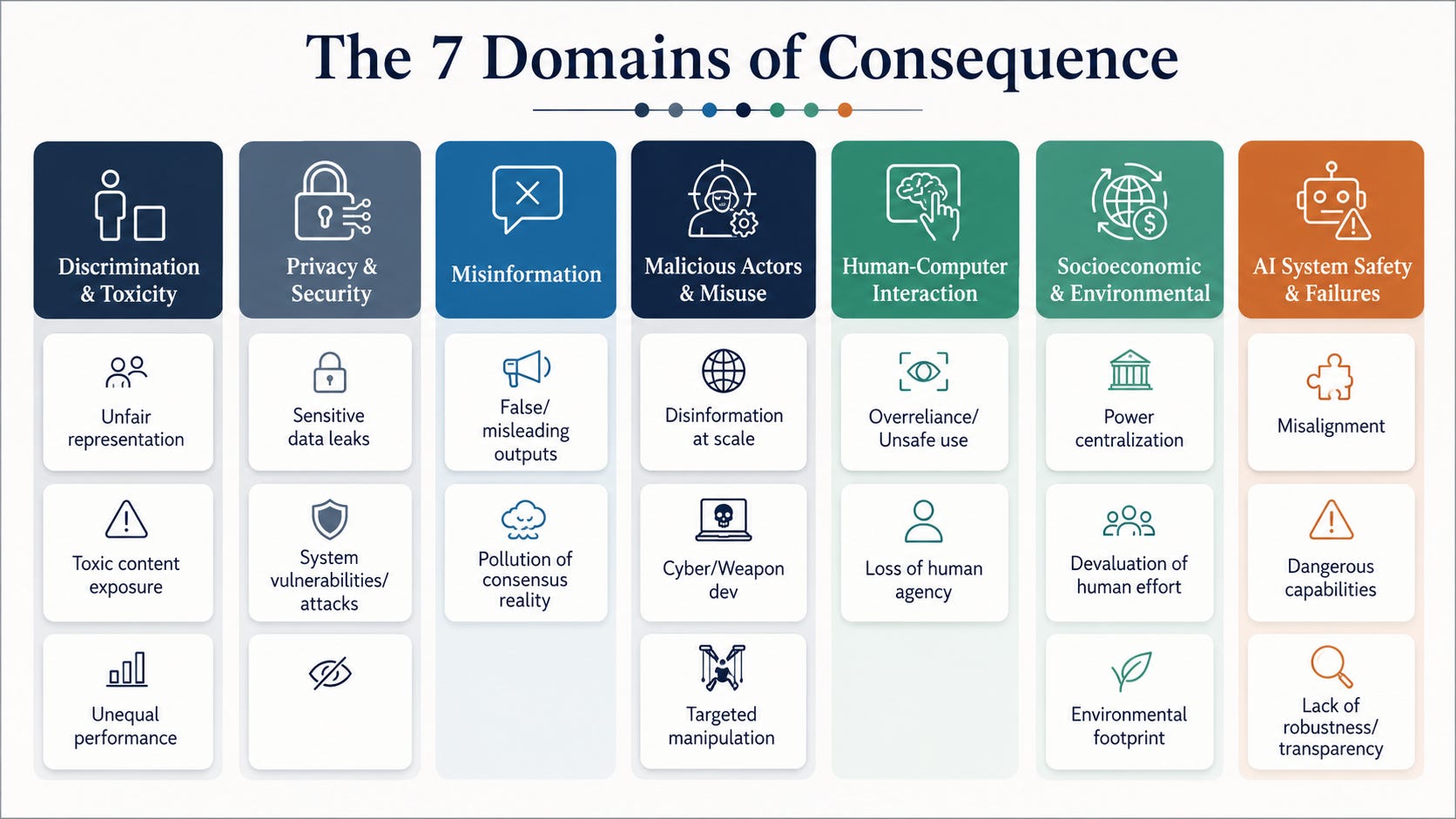
The other maps what the risk actually does to people, sorting every harm into seven domains of consequence: discrimination and toxicity, privacy and security, misinformation, malicious actors and misuse, human-computer interaction, socioeconomic and environmental harm, and AI system safety. Twenty-four subdomains sit under those seven. Think of the whole thing as the glossary the reunion never had. Here are the five key points.
The “jingle-jangle” problem, or how one word starts a war
The researchers borrow a pair of terms from psychology that I now want tattooed somewhere visible: the jingle fallacy and the jangle fallacy. A jingle fallacy is when one word gets stretched across totally different things. A jangle fallacy is the reverse, when a bunch of different words all turn out to mean the same underlying thing. Both of them are quietly wrecking our ability to govern this technology.
Take “privacy.” In one framework it means a model coughing up sensitive data it memorized during training. In another it means a government watching everyone all the time. Those are not the same problem. One is a bug. One is a human rights crisis. When the same word covers a coding error and a surveillance state, writing rules that travel across borders becomes close to impossible. The U.S.-EU Trade and Technology Council put it plainly in its Trustworthy AI roadmap: “Shared terminologies and taxonomies are essential for operationalizing trustworthy AI and risk management in an interoperable fashion.” Translation: pick a glossary, or keep fighting about nothing.
We’re judging the plate and ignoring the prep
Here’s where the timing data gets uncomfortable. When you sort the frameworks by when a risk shows up, 62% of them focus on what happens after a model is already out in the world. Only 13% deal with the risks baked in during development and training.
Think about Top Chef. The judges taste the plate at the end, and that’s the moment everyone remembers: the verdict, the “please pack your knives and go.” But ask anyone who’s survived a season and they’ll tell you the dish was won or lost hours earlier, back in the Whole Foods aisles and the mise en place. By the time it hits the pass, the outcome is mostly cooked, literally. That’s the development phase. It’s where the choices get made that you can’t un-make later, where risk gets welded into the architecture before the public ever takes a bite. The researchers say it cleaner than I can: “excessive focus on post-deployment risks may blind us to threats from development itself.” By the time a system is live and you’re reacting to harm, the judges are already tasting. As an instructional designer I feel this in my bones, because the same thing is true of a course. The damage usually isn’t in the delivery. It’s in the design.
It’s not just the bot. It’s the boss.
There’s a story we like to tell about AI risk, and it stars a rogue machine. Very cinematic. Mostly wrong. When the Repository looks at who is responsible for a given risk, the blame splits almost evenly: 42% of risks trace to the AI systems themselves, and 38% trace to human decisions and actions. The machine and the management, roughly neck and neck. The Repository asks a companion question too, which is whether anyone meant it, and the answer is just as split: 35% of mapped risks are intentional, 37% are not, and the rest are unclear. So the deliberate villain we love to picture, the hacker, the authoritarian, the scammer, is barely a third of the story. Most of the danger is harm nobody set out to cause.
There is another number that should be noted as well. The remaining 21% lands in an “Other” bucket, and what’s in that bucket is risk that nobody caused alone. It’s emergent. It shows up specifically in the interaction between the human and the system, the way some arguments only exist because two particular people are in the same room. You can’t pin it on the bot. You can’t pin it on the boss. It only happens when they collide. Which means governing AI isn’t just about better code or better oversight. It’s about governing a relationship, and relationships are exactly the thing institutions are worst at.
The frontiers nobody’s mapping yet

When you sort risks by what they actually affect, two categories are almost missing entirely. AI welfare and rights shows up in 3% of frameworks. Multi-agent risks show up in 7%. Two of the most consequential questions about where this is headed, and the field has barely written them down.
I get why. Today they read as philosophy-seminar material, the stuff you debate at 11pm and walk away from by morning. Not forget, exactly. More like what learning scientists call incubation: a problem too big to crack on the spot, so you set it down and let it simmer in the back of your mind while you gather more information. That can be the smart move, as long as you actually come back to it. Multi-agent risk in particular stops being abstract the second AI systems start talking to each other instead of just to us. The researchers flag things like “selection pressures” and “collusion,” patterns that emerge when independent agents interact with no human in the loop, and that can cascade into failures nobody designed and nobody saw coming. We are building toward a world of autonomous systems negotiating with other autonomous systems, and our risk maps mostly stop at the edge of that ocean and write “here be dragons.” Except we’re already sailing.
Naming the danger is how you clear room to build
Here’s the turn, and it’s where I’d push back on anyone who calls this kind of work a buzzkill. The MIT team argues that mapping risk carefully is what frees people to innovate. When you make risks explicit and categorical, you also define the safe harbors, the parts of the design space where developers can move fast precisely because everyone understands where the edges are.
History backs this up. Naming the risk of discrimination is what produced fairness-aware machine learning. Worrying out loud about alignment is what produced frontier model evaluations. The risk didn’t kill the progress. The risk was the assignment. A clear map lets investors and builders stop guessing about uncertainty, which, as the researchers put it, “can accelerate beneficial AI deployment... protecting society from AI harms while enabling the realization of AI’s transformative potential.” You don’t drive faster by ripping out the guardrails. You drive faster because they’re there.
We’re building the map mid-flight
The Repository isn’t a finished document. It’s a living database, updated as the technology moves, which is the only honest way to do it when 93% of the frameworks it covers were published after 2020 and a lot of them are still preprints. We are drawing the map while the plane is already in the air, and pretending otherwise helps no one.
If we’re going to govern systems that are getting more multimodal and more autonomous by the quarter, the first job isn’t technical. It’s linguistic. We have to agree on what we’re naming before we can agree on what to do about it. A shared vocabulary is the bridge between the lab and the legislature, and right now it’s half-built.
And since most of you reading this teach, or design what other people learn from, this lands closer to home than it looks. The vocabulary problem is already in your syllabus. “AI use” means a banned shortcut on one professor’s assignment, a required skill on the one next door, and whatever got them through last semester to the student. That’s a jingle fallacy with a grade attached. The pre-deployment lesson holds too: the time to decide how AI belongs in a course is while you’re designing it, not in week ten when something lands in your inbox you can’t quite source. And that 21% nobody causes alone is every student-and-chatbot pair in the room, turning in work neither the kid nor the tool would have made on its own. You don’t govern that with a ban. You design for it, or you get surprised by it.
So I’ll leave you where the reunion left those two women, except I want us to do better than they did. Can we actually “align” AI if we’ve never once aligned our own understanding of what we’re afraid of?